The Indirection Problem of LLM programming assistance

Programming has always been about managing complexity—finding ways to express our intentions to computers while maintaining human readability and understanding. Today, we face a new paradigm: generating code using large language models (LLMs). But is this solving the software development challenge, or are we adding another layer of indirection?
The Discourse of AI-assisted Programming
Observing the people on social media debating whether the software is solved with LLM paints a polarizing picture: while some are amazed at machines' ability to create code, experts remain skeptical of the capability of modern AI to replace them after seeing childish errors produced with infallible confidence of LLMs. However, many have begun using these tools as productivity boosters for routine tasks.
ML/AI educator Andrej Karpathy describes it as "vibe coding" - a term that captures the promise and, ironically, limitations of current LLM-based programming approaches. There is less substance in it beyond the vibe.
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper…
— Andrej Karpathy (@karpathy) February 2, 2025
The Fundamental Challenges
Several critical issues emerge when relying on LLMs for programming:
- LLMs hallucinate and, as a result, could generate code that looks plausible but contains subtle errors or inconsistencies that aren't immediately apparent or even miss the point entirely.
- Review Overhead: Code development becomes tiresome, as each generated segment must be carefully verified for correctness and consistency. This is something I've mentioned.
- Datasets used for training these models contain broken and low-quality code, which some (and me) may consider broken depending on the definition.
- The indirection we introduce multiplies ambiguity and introduces more points of breakage. This is a point I want to convey in this post.
The Source Code Illusion
One of the key insights in understanding this problem is recognizing that the source code itself is just one representation of software. When we write code, we're not directly creating software - we're making a human-readable specification that gets translated into machine code.
Consider these key points about the nature of software:
- Machine code is the actual software that executes and produces behavior
- Source code is just one possible way to specify that behavior
- The same source code can produce different machine code through different compilers
- Multiple source implementations can produce identical machine code
- Software can exist without corresponding high-level source code
The Problem with LLM Indirection
When we use LLMs to generate code, we're essentially adding another layer of indirection to an already indirect process:
Human Intent → LLM → Source Code → Compilation → Machine Code
Each step in this chain introduces the potential for errors and misunderstandings. While LLMs can help with the mechanical aspects of coding, they don't fundamentally solve the problem of precisely specifying what we want our software to do. If we zoom into compilation a bit, we'll see something like this:
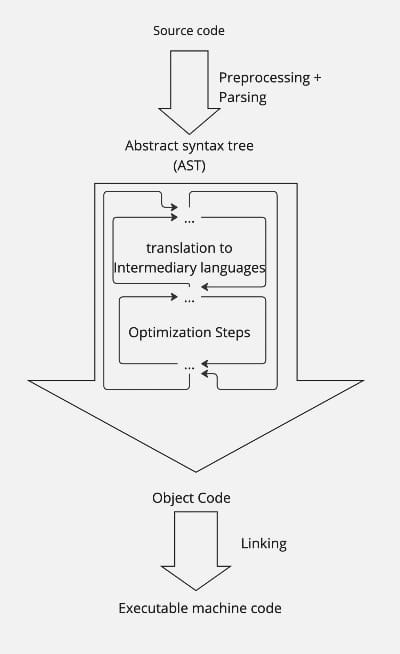
Not all of these steps are necessary for a machine to program another machine.
We can and should trim the steps needed for a human to teach the machine to describe computations.
Why do we have them in the first place? I'd argue that:
- During the first years of school, we all learn to read and write words and operate in paragraphs of text. We need this layer as human engineers to write, debug, and verify the programs.
- Compatible with existing tools, such as text editors and IDEs. Ideas for structural code editing have been floating around for decades, but there are still not many experts who use tools like these.
Firstly, we can teach AI to use a much lower level of programming. Secondly, we have no automated way to assess the quality of the produced code, which will only worsen the problem in the foreseeable future as generated code gets into the training datasets.
We need tools to verify the program we intend to write conforms to an external specification after we delegate the implementation to AI. More than that, we have methods to reduce the verification burden and turn some steps into a computational problem, allowing us to reuse our computational infrastructure for this job, too. These tools come from a domain of formal verification. It's a fascinating area of computer science, and we will explore it in further articles.
Moving Forward
However skeptical I am, we still have ways to improve and automate software development by creating processes on top of agentic LLMs.
So, rather than viewing LLMs as a solution to programming itself, we should see them as what they are: powerful but imperfect tools that can assist us with aspects of software development. The real breakthrough in automating software development will likely come from more fundamental changes in specifying and verifying software behavior.
This realization points us toward the need for more rigorous approaches to software specification and verification - topics that deserve their deep exploration in further articles.